


In Part 1 of this article we explored the current state of CGI, game, and contemporary VR systems. Here in Part 2 we look at the limits of human visual perception and show several of the methods we’re exploring to drive performance closer to them in VR systems of the future.
Guest Article by Dr. Morgan McGuire
Dr. Morgan McGuire is a scientist on the new experiences in AR and VR research team at NVIDIA. He’s contributed to the Skylanders, Call of Duty, Marvel Ultimate Alliance, and Titan Quest game series published by Activision and THQ. Morgan is the coauthor of The Graphics Codex and Computer Graphics: Principles & Practice. He holds faculty positions at the University of Waterloo and Williams College.

Note: Part 1 of this article provides important context for this discussion, consider reading it before proceeding.
Reinventing the Pipeline for the Future of VR
We derive our future VR specifications from the limits of human perception. There are different ways to measure these, but to make the perfect display you’d need roughly the equivalent to 200 HDTVs updating at 240 Hz. This equates to about 100,000 megapixels per second of graphics throughput.
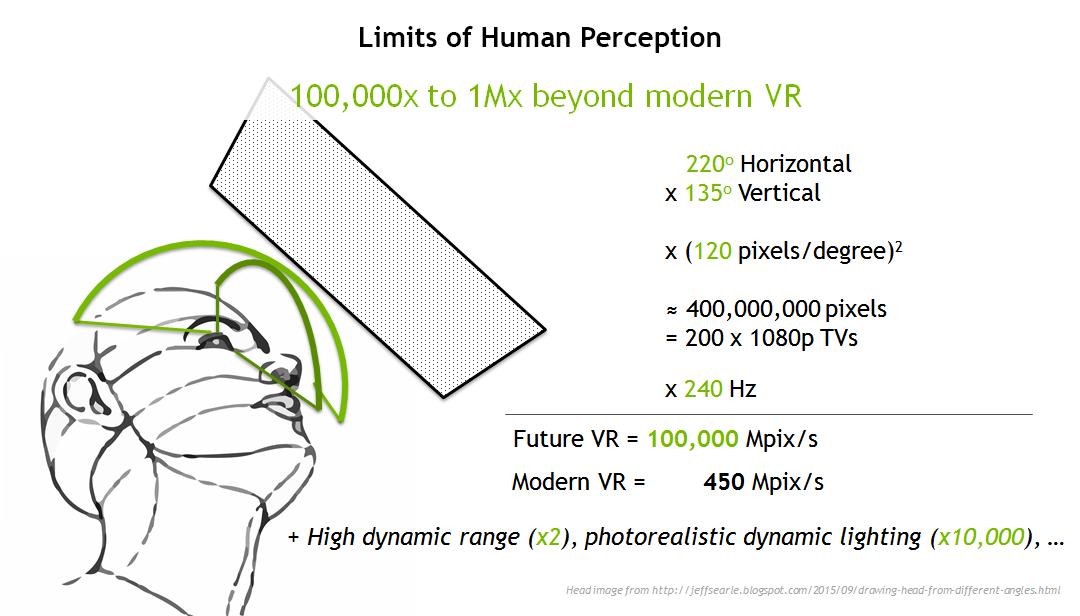
We could theoretically accomplish this by committing increasingly greater computing power, but brute force simply isn’t efficient or economical. Brute force won’t get us to pervasive use of VR. So, what techniques can we use to get there?
Rendering Algorithms
Foveated Rendering
Our first approach to performance is the foveated rendering technique—which reduces the quality of images in a user’s peripheral vision—takes advantage of an aspect of human perception to generate an increase in performance without a perceptible loss in quality.


Light Fields
To speed up realistic graphics for VR, we’re looking at rendering primitives beyond just today’s triangle meshes. In this collaboration with McGill and Stanford we’re using light fields to accelerate the lighting computations. Unlike today’s 2D light maps that paint lighting onto surfaces, these are a 4D data structure that stores the lighting in space at all possible directions and angles.

Real-time Ray Tracing
What about true run-time ray tracing? The NVIDIA Volta GPU is the fastest ray tracing processor in the world, and its NVIDIA Pascal GPU siblings are the fastest consumer ones. At about 1 billion rays/second, Pascal is just about fast enough to replace the primary rasterizer or shadow maps for modern VR. If we unlock the pipeline with the kinds of changes I’ve just described, what can ray tracing do for future VR?
The answer is: ray tracing can do a lot for VR. When you’re tracing rays, you don’t need shadow maps at all, thereby eliminating a latency barrier Ray tracing can also natively render red, green, and blue separately, and directly render barrel-distorted images for the lens. So, it avoids the need for the lens warp processing and the subsequent latency.
In fact, when ray tracing, you can completely eliminate the latency of rendering discrete frames of pixels so that there is no ‘frame rate’ in the classic sense. We can send each pixel directly to the display as soon as it is produced on the GPU. This is called ‘beam racing’ and eliminates the display synchronization. At that point, there are zero high-latency barriers within the graphics system.
Because there’s no flat projection plane as in rasterization, ray tracing also solves the field of view problem. Rasterization depends on preserving straight lines (such as the edges of triangles) from 3D to 2D. But the wide field of view needed for VR requires a fisheye projection from 3D to 2D that curves triangles around the display. Rasterizers break the image up into multiple planes to approximate this. With ray tracing, you can directly render even a full 360 degree field of view to a spherical screen if you want. Ray tracing also natively supports mixed primitives: triangles, light fields, points, voxels, and even text, allowing for greater flexibility when it comes to content optimization. We’re investigating ways to make all of those faster than traditional rendering for VR.
In addition to all of the ways that ray tracing can accelerate VR rendering latency and throughput, a huge feature of ray tracing is what it can do for image quality. Recall from the beginning of this article that the image quality of film rendering is due to an algorithm called path tracing, which is an extension of ray tracing. If we switch to a ray-based renderer, we unlock a new level of image quality for VR.
Real-time Path Tracing
Although we can now ray trace in real time, there’s a big challenge for real-time path tracing. Path tracing is about 10,000x more computationally intensive than ray tracing. That’s why movies takes minutes per frame to generate instead of milliseconds.
Under path tracing, the system first traces a ray from the camera to find the visible surface. It then casts another ray to the sun to see if that surface is in shadow. But, there’s more illumination in a scene than directly from the sun. Some light is indirect, having bounced off the ground or another surface. So, the path tracer then recursively casts another ray at random to sample the indirect lighting. That point also requires a shadow ray cast, and its own random indirect light…the process continues until it has traced about about 10 rays for each single path.
But if there’s only one or two paths at a pixel, the image is very noisy because of the random sampling process. It looks like this:

To unlock path tracing image quality for VR, we need a way to sample only a few paths per pixel and still avoid the noise from random sampling. We think we can get there soon thanks to innovations like foveated rendering, which makes it possible to only pay for expensive paths in the center of the image, and denoising, which turns the grainy images directly into clear ones without tracing more rays.
We released three research papers this year towards solving the denoising problem. These are the result of collaborations with McGill University, the University of Montreal, Dartmouth College, Williams college, Stanford University, and the Karlsruhe Institute of Technology. These methods can turn a noisy, real-time path traced image like this:


Computational Displays
The displays in today’s VR headsets are relatively simple output devices. The display itself does hardly any processing, it simply shows the data that is handed to it. And while that’s fine for things like TVs, monitors, and smartphones, there’s huge potential for improving the VR experience by making displays ‘smarter’ about not only what is being displayed but also the state of the observer. We’re exploring several methods of on-headset and even in-display processing to push the limits of VR.
Solving Vergence-Accommodation Disconnect
The first challenge for a VR display is the focus problem, which is technically called the ‘vergence-accommodation disconnect’. All of today’s VR and AR devices force you to focus about 1.5m away. That has two drawbacks:
- When you’re looking at a very distant or close up object in stereo VR, the point where your two eyes converge doesn’t match the point where they are focused (‘accommodated’). That disconnect creates discomfort and is one of the common complaints with modern VR.
- If you’re using augmented reality, then you are looking at points in the real world at real depths. The virtual imagery needs to match where you’re focusing or it will be too blurry to use. For example, you can’t read augmented map directions at 1.5m while you’re looking 20m into the distance while driving.

That first light field display was from 2013. Next week, at the ACM SIGGRAPH Asia 2018 conference, we’re presenting a new holographic display that uses lasers and intensive computation to create light fields out of interfering wavefronts of light. It is harder to visualize the workings here, but relies on the same underlying principles and can produce even better imagery.
We strongly believe that this kind of in-display computation is a key technology for the future. But light fields aren’t the only approach that we’ve taken for using computation to solve the focus problem. We’ve also created two forms of variable-focus, or ‘varifocal’ optics.
This display prototype projects the image using a laser onto a diffusing hologram. You look straight through the hologram and see its image as if it was in the distance when it reflects off a curved piece of glass:

This approach requires two pieces of computation in the display: one tracks the user’s eye and the other computes the correct optics in order to render a dynamically pre-distorted image. As with most of our prototypes, the research version is much larger than what would become an eventual product. We use large components to facilitate research construction. These displays would look more like sunglasses when actually refined for real use.
Here’s another varifocal prototype, this one created in collaboration with researchers at the University of North Carolina, the Max Planck Institute, and Saarland University. This is a flexible lens membrane. We use computer-controlled pneumatics to bend the lens as you change your focus so that it is always correct.
Hybrid Cloud Rendering
We have a variety of new approaches for solving the VR latency challenge. One of them, in collaboration with Williams College, leverages the full spread of GPU technology. To reduce the delay in rendering, we want to move the GPU as close as possible to the display. Using a Tegra mobile GPU, we can even put the GPU right on your body. But a mobile GPU has less processing power than a desktop GPU, and we want better graphics for VR than today’s games… so we team the Tegra with a discrete GeForce GPU across a wireless connection, or even better, to a Tesla GPU in the cloud.

Reducing the Latency Baseline
Of course, you can’t push latency to less than the frame rate. If the display updates at 90 FPS, then it is impossible to have latency less than 11 ms in the worst case, because that’s how long the display waits between frames. So, how fast can we make the display?
We collaborated with scientists at the University of North Carolina to build a display that runs at sixteen thousand binary frames per second. Here’s a graph from a digital oscilloscope showing how well this works for the crucial case of a head turning. When you turn your head, latency in the screen update causes motion sickness.
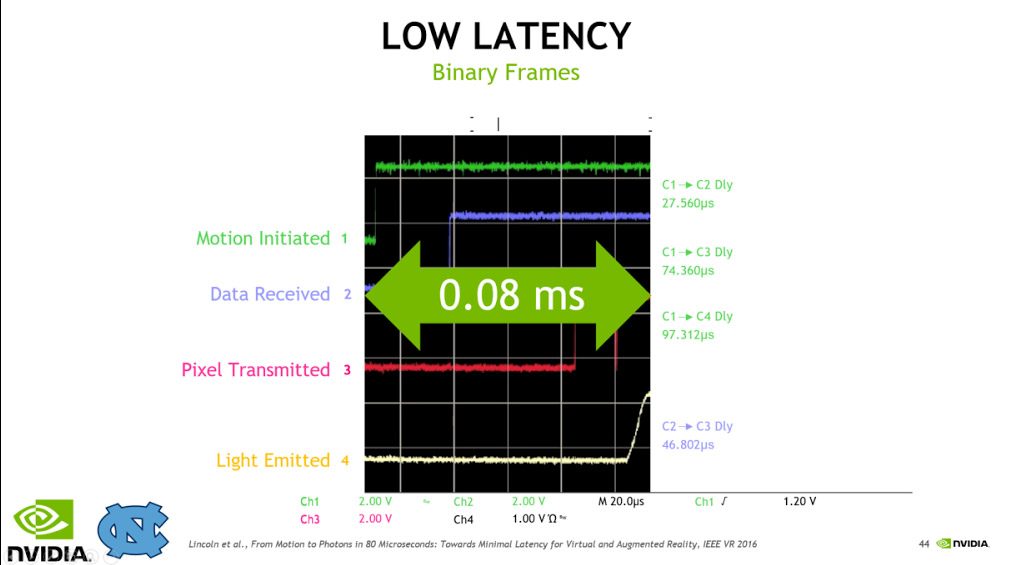
The renderer can’t run at 16,000 fps, so this kind of display works by Time Warping the most recent image to match the current head position. We speed that Time Warp process up by running it directly on the head-mounted display. Here’s an image of our custom on-head processor prototype for this:

The Complete System
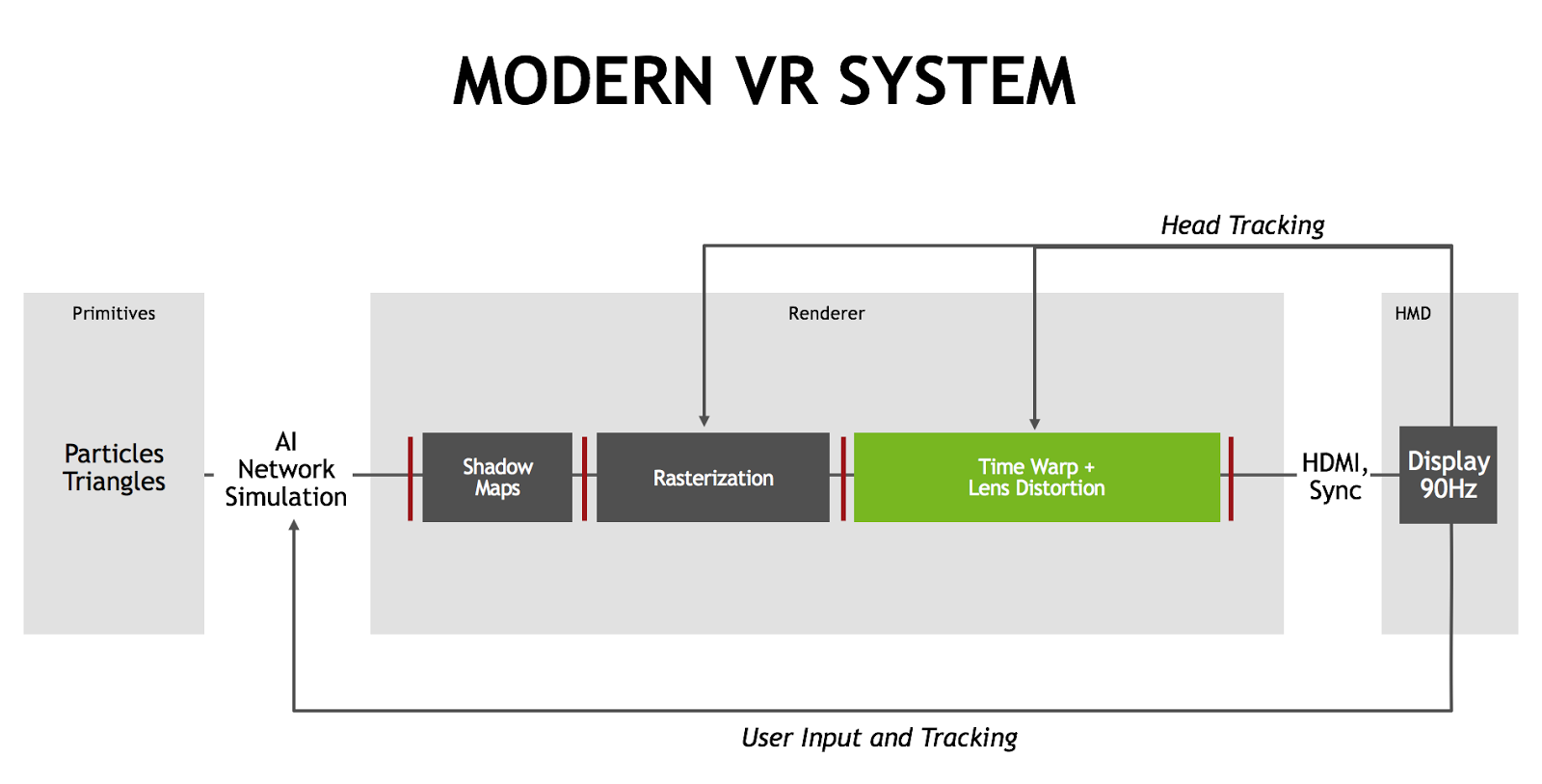
As a reminder, in Part 1 of this article we identified the rendering pipeline employed by today’s VR headsets:
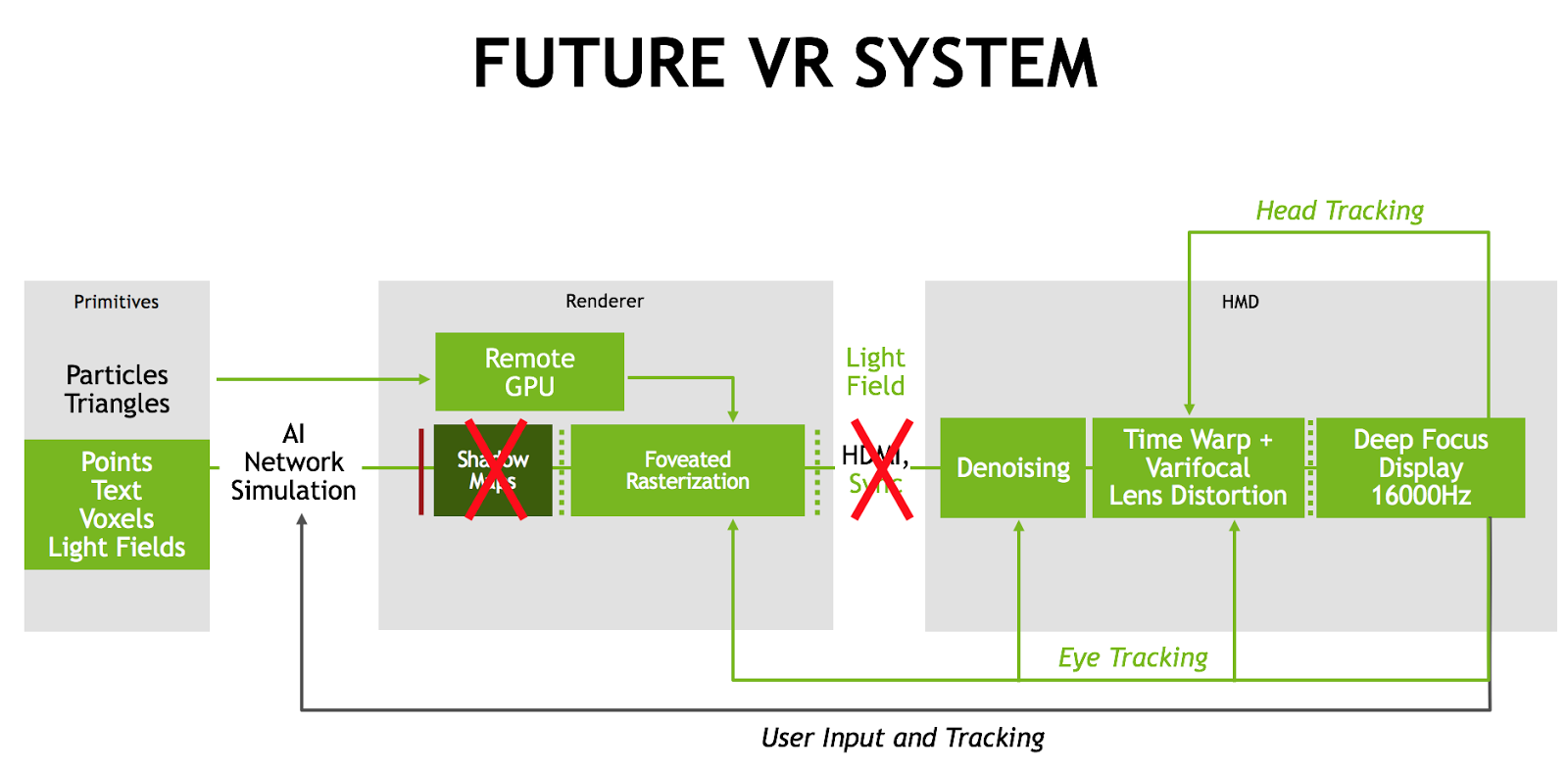
By breaking ground in the areas of computational displays, varifocal optics, foveated rendering, denoising, light fields, binary frames and others, NVIDIA Research is innovating for a new system for virtual experiences. As systems become more comfortable, affordable and powerful, this will become the new interface to computing for everyone.
All of the methods that I’ve described can be found in deep technical detail on our website.
I encourage everyone to experience the great, early-adopter modern VR systems available today. I also encourage you to join us in looking to the bold future of pervasive AR/VR/MR for everyone, and recognize that revolutionary change is coming through this technology.

