")
Facebook Reality Labs, the company’s AR/VR R&D group, published detailed research on a method for hyper-realistic real-time virtual avatars, expanding on prior work which the company calls ‘Codec Avatars’.
Facebook Reality Labs has created a system capable of animating virtual avatars in real-time with unprecedented fidelity from compact hardware. From just three standard cameras inside the headset, which capture the user’s eyes and mouth, the system is able to represent the nuances of a specific individual’s complex face gestures more accurately than previous methods.
More so than just sticking cameras on to a headset, the thrust of the research is the technical magic behind using the incoming images to drive a virtual representation of the user.
The solution relies heavily on machine learning and computer vision. “Our system runs live in real-time and it works for a wide range of expressions, including puffed-in cheeks, biting lips, moving tongues, and details like wrinkles that are hard to be precisely animated for previous methods,” says one of the authors.
Facebook Reality Labs published a technical video summary of the work to coincide with SIGGRAPH 2019:
The group also published their full research paper, which dives even deeper into the methodology and math behind the system. The work, ‘VR Facial Animation via Multiview Image Translation’, was published in ACM Transactions on Graphics, which is self-described as the “foremost peer-reviewed journal in graphics.” The paper is authored by Shih-En Wei, Jason Saragih, Tomas Simon, Adam W. Harley, Stephen Lombardi, Michal Perdoch, Alexander Hypes, Dawei Wang, Hernan Badino, Yaser Sheikh.

The paper explains how the project involved the creation of two separate experimental headsets, a ‘Training’ headset and a ‘Tracking’ headset.
The Training headset is bulkier and uses nine cameras which allow it to capture a wider range of views of the subject’s face and eyes. Doing so makes easier the task of finding the ‘correspondence’ between the input images and a previously captured digital scan of the user (deciding which parts of the input images represent which parts of the avatar). The paper says that this process is “automatically found through self-supervised multiview image translation, which does not require manual annotation or one-to-one correspondence between domains.”
Once correspondence is established, the more compact ‘Tracking’ headset can be used. The alignment of its three cameras mirror three of the nine cameras on the ‘Training’ headset; the views of these three cameras are better understood thanks to the data collected from the ‘Training’ headset, which allows the input to accurately drive animations of the avatar.
The paper focuses heavily on the accuracy of the system. Prior methods create lifelike output, but the accuracy of the user’s actual face compared to the representation breaks down in key areas, especially with extreme expressions and the relationship between what the eyes are doing and what the mouth is doing.
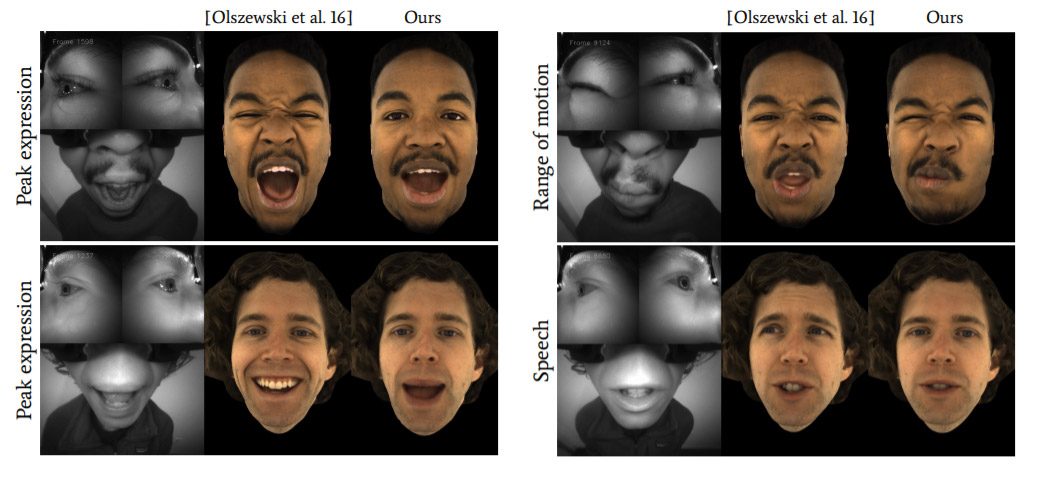
The work is especially impressive when you take a step back at what’s actually happening here: for a user whose face is largely obscured by a headset, extremely close camera shots are being used to accurately rebuild an unobscured view of the face.
As impressive as it is, the approach still has major hurdles preventing mainstream adoption. The reliance on both a detailed preliminary scan of the user and the initial need to use the ‘Training’ headset would necessitate something along the lines of ‘scanning centers’ where users could go to have their avatar scanned and trained (might as well capture a custom HRTF while you’re at it!). Until VR is a significant part of the way society communicates, it seems unlikely that such centers would be viable. However, advanced sensing technologies and continued improvements in automatic correspondence building atop this work could eventually lead to a viable in-home process.





