Meta has introduced the Segment Anything Model, which aims to set a new bar for computer-vision-based ‘object segmentation’—the ability for computers to understand the difference between individual objects in an image or video. Segmentation will be key for making AR genuinely useful by enabling a comprehensive understanding of the world around the user.
Object segmentation is the process of identifying and separating objects in an image or video. With the help of AI, this process can be automated, making it possible to identify and isolate objects in real-time. This technology will be critical for creating a more useful AR experience by giving the system an awareness of various objects in the world around the user.
The Challenge
Imagine, for instance, that you’re wearing a pair of AR glasses and you’d like to have two floating virtual monitors on the left and right of your real monitor. Unless you’re going to manually tell the system where your real monitor is, it must be able to understand what a monitor looks like so that when it sees your monitor it can place the virtual monitors accordingly.
But monitors come in all shapes, sizes, and colors. Sometimes reflections or occluded objects make it even harder for a computer-vision system to recognize.
Having a fast and reliable segmentation system that can identify each object in the room around you (like your monitor) will be key to unlocking tons of AR use-cases so the tech can be genuinely useful.
Computer-vision based object segmentation has been an ongoing area of research for many years now, but one of the key issues is that in order to help computers understand what they’re looking at, you need to train an AI model by giving it lots images to learn from.
Such models can be quite effective at identifying the objects they were trained on, but if they will struggle on objects they haven’t seen before. That means that one of the biggest challenges for object segmentation is simply having a large enough set of images for the systems to learn from, but collecting those images and annotating them in a way that makes them useful for training is no small task.
SAM I Am
Meta recently published work on a new project called the Segment Anything Model (SAM). It’s both a segmentation model and a massive set of training images the company is releasing for others to build upon.
The project aims to reduce the need for task-specific modeling expertise. SAM is a general segmentation model that can identify any object in any image or video, even for objects and image types that it didn’t see during training.
SAM allows for both automatic and interactive segmentation, allowing it to identify individual objects in a scene with simple inputs from the user. SAM can be ‘prompted’ with clicks, boxes, and other prompts, giving users control over what the system is attempting to identifying at any given moment.
It’s easy to see how this point-based prompting could work great if coupled with eye-tracking on an AR headset. In fact that’s exactly one of the use-cases that Meta has demonstrated with the system:
Here’s another example of SAM being used on first-person video captured by Meta’s Project Aria glasses:
You can try SAM for yourself in your browser right now.
How SAM Knows So Much
Part of SAM’s impressive abilities come from its training data which contains a massive 10 million images and 1 billion identified object shapes. It’s far more comprehensive than contemporary datasets, according to Meta, giving SAM much more experience in the learning process and enabling it to segment a broad range of objects.
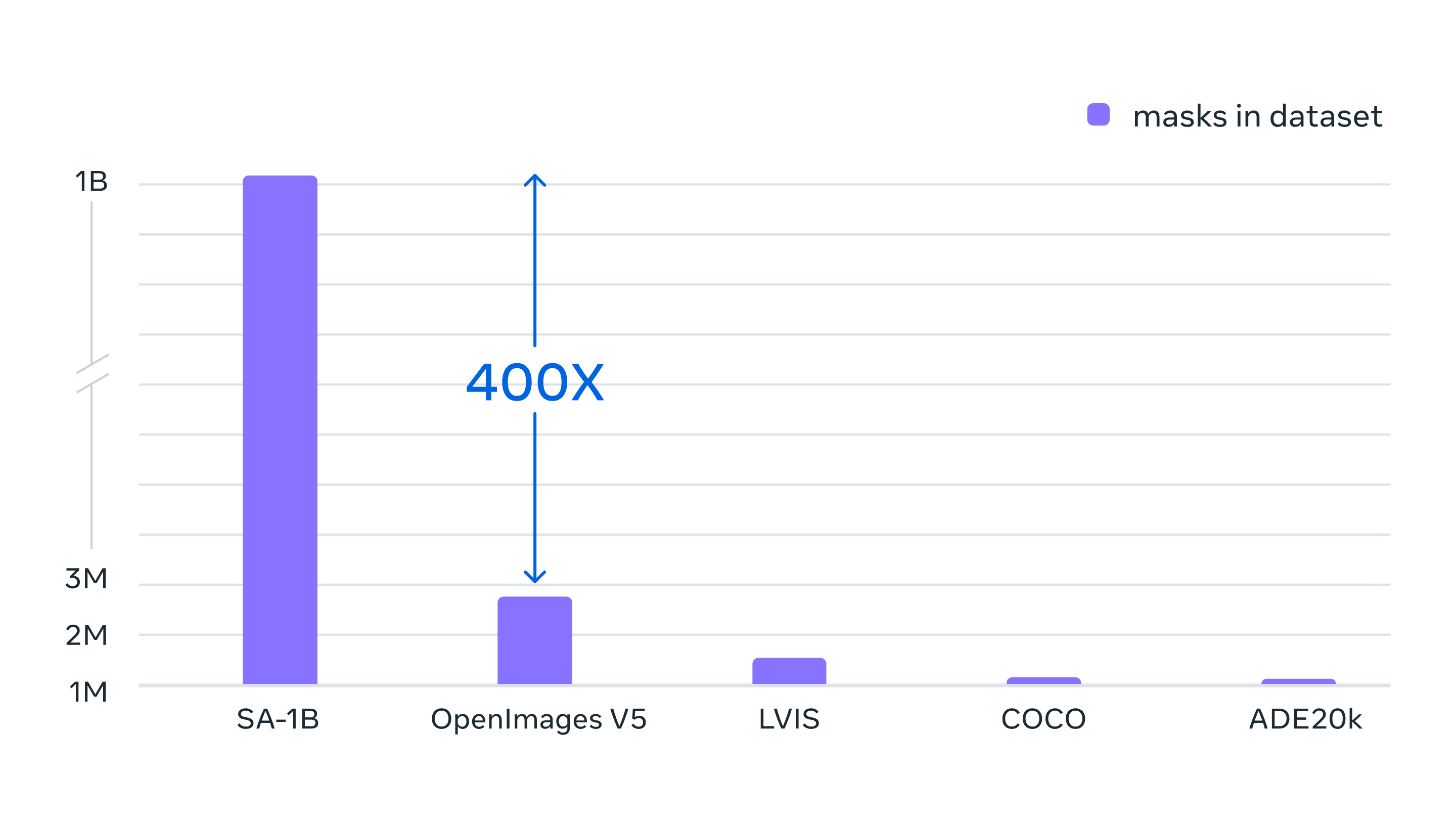{kind=link}
Meta calls the SAM dataset SA-1B, and the company is releasing the entire set for other researchers to build upon.
Meta hopes this work on promptable segmentation, and the release of this massive training dataset, will accelerate research into image and video understanding. The company expects the SAM model can be used as a component in larger systems, enabling versatile applications in areas like AR, content creation, scientific domains, and general AI systems.